How to solve the SKU changeover bottleneck with a self-learning vision system
Key Highlights
- In high-mix environments, vision systems fail not because of poor accuracy, but because the manual process of data collection, labeling and training takes longer than the production run of the SKU itself.
- Self-learning systems do not continuously change their logic, which would break industrial determinism; instead, they eliminate engineering overhead by building an inspection baseline directly from live production data in minutes.
- Vision systems that can focus on learning the specific normal baseline of a station can flag any anomaly, even those never seen before.


SRIVATSAV NAMBI
ELEMENTARY ML
AI & Smart Automation, Machine Vision, Imaging & Inspection
Srivatsav Nambi, founding AI scientist at Elementary ML, will present "Self-Learning Vision Systems Get Smarter Over Time: The Next Frontier in Machine Perception" at 8 am on June 22 during A3's Automate 2026 in Chicago.
The session will examine why traditional vision systems often succeed at commissioning but fail months later as production conditions evolve. In modern manufacturing environments, changes in lighting, surface texture, product geometry and process variability continuously shift what “normal” looks like, exposing a mismatch between static, dataset-driven approaches and real production dynamics.
Rather than relying on offline data collection and periodic retraining, self-learning vision systems redefine how inspection baselines are established by learning directly from live production while maintaining deterministic, auditable behavior. The talk presents a system-level framework for shifting baseline definition to the production line, enabling startup in minutes instead of hours or days while eliminating much of the manual data collection and tuning traditionally required.
It covers how systems build stable baselines from representative production data, transition from startup to steady-state operation and apply updates as explicit, traceable events rather than continuous model drift. It also addresses integration with PLC-driven workflows, model versioning and scaling inspection across multiple stations without increasing engineering overhead.
The talk positions self-learning inspection within a broader shift in machine perception, from static models built offline to systems that learn from real-world operation while maintaining control, traceability and reliability in production environments.
Most vision systems don't fail at commissioning. They fail to deliver promised results six months later.
In high-mix production environments, a stock keeping unit (SKU) may only run for four to six hours before changeover. By the time a traditional vision system collects data, labels it, trains a model and deploys it, the SKU is already gone. Even in the best case, this process takes one to two hours, and in many cases longer. That means a significant portion of production runs completely uninspected.
This is not a tooling limitation. It is a fundamental mismatch between how vision systems are built and how manufacturing operates. As SKU counts increase, product lifecycles shrink. A line that once ran a single product for weeks now cycles through dozens of variants in a day, turning what used to be a stable inspection problem into a continuously changing one.
Twenty years ago, a product like Head & Shoulders shampoo might have had a single SKU on the shelf. Now, it exists in many variants with different sizes, formulations, packaging and labeling. Each variant may only run on the line for a few hours, and, by the time a conventional vision system is configured, that SKU has already passed through production.
In practice, this means a large portion of SKUs are either partially inspected or not inspected at all.
They fail because they cannot keep up with production. A line that passed acceptance in March starts flagging good parts in September. A changeover that used to take 30 minutes now takes weeks. An integrator gets called back to retune thresholds after a supplier shifts surface finish within spec.
The system was not wrong about defects. It was wrong about what is normal.
For anyone running multiple inspection points, this is the real cost of vision. Detection accuracy matters, but accuracy alone is not enough. Deployment time, maintenance effort and the ability to hold performance across shifts and changeovers determine whether a vision system actually works at scale.
Every one of these factors translates directly into cost. Engineering hours spent collecting parts, labeling data and revalidating thresholds are hours not spent on other inspection points. Weeks of commissioning delay line qualification and a station that drifts out of spec produces suspect parts until someone intervenes.
The time spent before a system can inspect anything and the time spent maintaining it after deployment are where most of the real cost lives.
To make inspection viable in these environments, the system must meet a different set of constraints. It must start working in minutes, not hours or days. It must require no manual data collection or labeling, and it must adapt to each SKU without human intervention.
This is not an optimization problem. It is a constraint imposed by how production lines operate.
A newer class of systems, often called self-learning systems, is designed around these constraints. The term is often misunderstood, so it is important to be precise about what these systems actually do.
What self-learning actually means
Self-learning does not mean a model that continuously modifies itself in production. That would break determinism, traceability and validation. No controls engineer or quality engineer should accept a system that changes behavior without explicit control.
What self-learning actually means is that the system builds its inspection baseline by observing the line, instead of requiring engineers to collect and label a dataset before deployment. Once the baseline is established, the system runs deterministic inference against it, and updates after that are explicit events such as operator feedback that is logged and reviewed or new model versions pushed from a central platform.
The model does not drift on its own.
The value is not continuous adaptation. The value is eliminating the need for offline data collection and manual tuning while preserving deterministic behavior. These steps are expensive and show up as engineering time, delayed deployments and inspection points that are never automated because the setup cost does not justify the effort.
Rule-based or trained systems
A rule-based or trained vision system assumes that acceptable conditions can be defined in advance. Engineers tune against expected lighting, expected parts and expected materials, and models are trained on datasets assembled before the line runs at scale.
The workflow is familiar: collect parts, label them, train or tune, deploy, validate and repeat when conditions change.
On a stable line, this may be acceptable. Across a plant with multiple inspection points and frequent changeovers, each station carries its own engineering overhead, and that overhead compounds.
Trained systems also require examples of the defects they are expected to detect. Rare defects, often the most critical ones, are underrepresented in any dataset assembled in advance. The system detects what it has seen and misses what it has not.
Moving baseline definition to the line
Self-learning systems change where and when the baseline is defined. Instead of defining normal through an offline dataset, the system learns it directly from live production during a short startup window. There is no separate data collection phase, and normal is defined by what the line produces consistently.
Each station learns its own baseline from its own environment. A packaging inspection station and an automotive inspection station do not share the same model, even within the same plant. Each adapts to its specific parts, lighting, fixturing and variability.
The architecture that supports this approach typically combines a centralized foundation model with edge-based adaptation. The foundation model is trained centrally on a broad dataset and provides general understanding of visual patterns, while the edge system adapts this foundation to the specific production environment by observing real parts.
Get your subscription to Control Design’s daily newsletter.
The foundation provides generalization. The edge provides specificity.
For commissioning, the impact is straightforward. Startup is measured in minutes, rather than weeks. The system observes parts, builds its baseline and then switches to inference. Once this transition occurs, the model is fixed, and every part is evaluated against the same baseline with results produced within cycle time.
For plants deploying inspection across multiple lines, the reduction in setup time is often what makes automation economically viable.
Runtime behavior
At runtime, the system behaves like a standard inspection node. A part arrives, the controller analyzes the image, and in steady operation the part is classified as normal or defect with the result produced within cycle time.
If the system is still in its startup phase, incoming parts are evaluated for whether they are representative of the process. Representative parts are added to the baseline, while others are ignored. No classification output is generated during this phase, and downstream logic handles this as a standard inspection warmup.
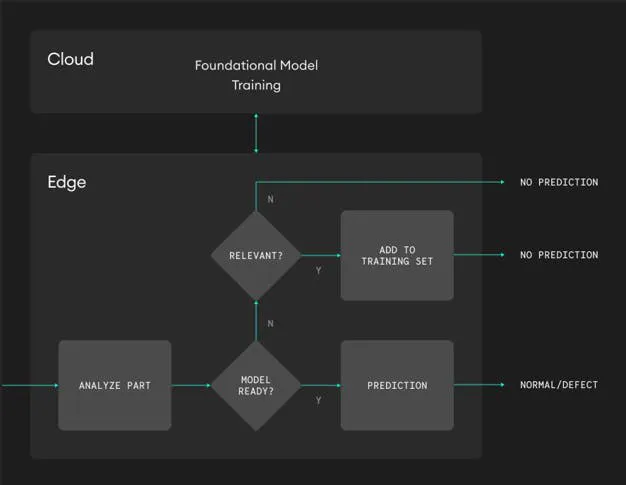
Integration and determinism
From an integration perspective, a properly designed self-learning system behaves like any other inspection component. It provides deterministic pass or fail outputs within cycle time, is triggered by the programmable logic controller (PLC) through standard interfaces, runs at the edge for predictable latency and logs results to the supervisory control and data acquisition (SCADA) system or manufacturing execution system (MES) without requiring changes to the broader control architecture.
There are several practical considerations when evaluating such systems. Model versioning is critical, since each baseline is derived from production data and must be traceable. A robust system logs model versions alongside inspection results and treats updates as discrete, auditable events.
Operator feedback must also be handled carefully. Overrides and confirmations should be logged, authenticated and clearly separated from immediate system behavior, with feedback informing future updates without altering current deterministic operation.
Finally, fleet management is required to scale. While each station learns independently, a centralized layer is needed to manage multiple stations, distribute updates and aggregate data across the plant.
Where self-learning vision fits
Self-learning systems are most effective in environments where variation is continuous but bounded, where defect modes are not fully known in advance and where deployment speed and engineering effort are critical constraints.
High-mix packaging lines, where SKUs change frequently, are a natural fit. Food and beverage environments, where natural variation is inherent, also benefit, as do electronics manufacturing lines with short product cycles.
In these environments, conventional approaches either fail to scale or become too costly to maintain.
Rare-defect scenarios highlight another advantage. Systems that learn normal conditions and flag deviations can detect anomalies without requiring prior examples of every defect type.
This is not a replacement for all inspection methods. Some applications require explicit defect classification and predefined fault categories, and in those cases conventional models remain appropriate.
However, for a large and growing class of inspection problems, moving baseline definition to the production line changes the economics of deployment.
In high-mix environments, the key question is no longer whether a system is accurate. The question is whether it can start fast enough to matter. If a system takes hours to deploy and a SKU lasts only a few hours, the system is effectively never in production.
Self-learning systems address this mismatch directly by aligning deployment speed with production speed.
For engineers responsible for multiple inspection points, this reduces time spent on dataset curation and system maintenance while increasing time spent on scaling inspection coverage. For manufacturers, it shifts vision systems from isolated projects to a scalable capability across the plant.
Self-learning systems define normal on the line, under real conditions, and then hold it steady. That shift is what allows vision systems to operate reliably in manufacturing production environments.
About the Author

Srivatsav Nambi
Elementary ML
Srivatsav Nambi is the founding AI scientist and architect at Elementary, specializing in industrial AI and robotic perception. His work focuses on building and deploying AI-driven perception and inspection systems in real-world manufacturing environments. He has played a key role in systems deployed across hundreds of production lines, enabling high-throughput inspection and traceability at industrial scale. He is a named inventor on multiple patents in robotic perception and inspection, with citations from organizations including Amazon, GE, IBM and Airbus. Contact him at [email protected].

Leaders relevant to this article: